First of all, I need to explain why I decided to write such a post. It's quite simple to everyone who ever tried to Deploy/Configure/Understand how Cisco ACI works using the official Cisco Documentation. Cisco ACI is a very powerful architecture, and once you learn it - you start loving it. My assumption is that for some reason, Cisco seems to have hired the App Development experts to develop the ACI GUI and the ACI design and configuration guides, and the final product turned out to be hard to digest to both, DevOps and Networking professionals. That is why I feel there is a need to explain the concepts in a way more easy to understand for us, humans.
TIP: APIC maintains an audit log for all configuration changes to the system. This means that all the changes can be easily reverted.
Before the ACI installation starts, we need to connect every ACI controller (APIC) to 2 Leafs. There should be 3 or 5 APICs, for high availability, and a standard procedure, once the cabling is done, should be:
- Turn ON and perform a Fabric Discovery.
- Configure Out-of-Band Management.
- Configure the NTP Server in Fabric Policies -> POD Policies” menu. This is very important, because if the Fabric and the Controllers are in different time zones for example, the ACI wont synchronise correctly.
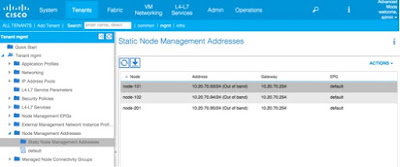
Once the Fabric Discovery is done, you need to enter the mgmt tenant, and within the Node Management Addresses create the Static Entries for all your nodes. In our case, we have 3 nodes: Spine (201) and 2 Leafs (101 and 102). This means that since the nodes are not consecutive, you should create 2 Static Entries, one for nodes 101-102, and the second one for the node 201. You should choose the “default” Node Management EPG for now, and you will end up with:
When we are looking at a real world ACI deployment, in the Typical Migration Scenario a client would want us to migrate 2 different environments:
-
Virtual Environment, where we would need to first define all VM types and "group" them (define EPGs).
-
Physical Environment.
Once we have the environments defined, we need to build the ANPs (Application Network Profiles), where we will group all the EPGs that need to inter-communicate.
Once we did the initial design, we need to make a list of all the tasks we need to do, and start building up the Tenants. Be sure you understand what Infra and Common tenants are before you start planning the Configuration. Configuration objects in the Common tenant are shared with all other tenants (things that affect the entire fabric):
-
Private Networks (Context or VRF)
-
Bridge Domains
-
Subnets
1. Physical Connectivity/Fabric Policies
The communication with the outside world (external physical network) starts by a simple question: Who from the outside world needs to access the "Service" (ANP in the ACI "language"). Once we have this answered, we need to define a EPG with these users. Let´s say the financial department needs to access the ANP, which is a Salary Application. We will create the EPG called "Financial_EPG" which might be an External L2 EPG where we group all the guys from Finances. This EPG will access the Financial Application Web Server, so the Financial_Web_EPG will need a PROVIDER CONTRACT allowing the access to Financial_Department_EPG.
Domains are used to interconnect the Fabric configuration with the Policy configuration. Different domain types are created depending on how a device is connected to the leaf switch. There are four different domain types:
-
Physical domains, for physical servers (no hypervisor).
-
External bridged domains, for a connection to L2 Switch via dot1q trunk.
-
External routed domains, for a connection to a Router/WAN Router.
-
VMM domains, which are used for Hypervisor integration. 1 VMM domain per 1 vCenter Data Center.
The ACI fabric provides multiple attachment points that connect through leaf ports to various external entities such as baremetal servers, hypervisors, Layer 2 switches (for example, the Cisco UCS fabric interconnect), and Layer 3 routers (for example Cisco Nexus 7000 Series switches). These attachment points can be physical ports, port channels, or a virtual port channel (vPC) on the leaf switches.
VLANs are instantiated on leaf switches based on AEP configuration. An attachable entity profile (AEP) represents a group of external entities with similar infrastructure policy requirements. The fabric knows where the various devices in the domain live and the APIC can push the VLANs and policy where it needs to be. AEPs are configured under global policies. The infrastructure policies consist of physical interface policies, for example, Cisco Discovery Protocol (CDP), Link Layer Discovery Protocol (LLDP), maximum transmission unit (MTU), and Link Aggregation Control Protocol (LACP). A VM Management (VMM) domain automatically derives the physical interfaces policies from the interface policy groups that are associated with an AEP.
VLAN pools contain the VLANs used by the EPGs the domain will be tied to. A domain is associated to a single VLAN pool. VXLAN and multicast address pools are also configurable. VLANs are instantiated on leaf switches based on AEP configuration. Forwarding decisions are still based on contracts and the policy model, not subnets and VLANs. Different overlapping VLAN pools must not be associated with the same attachable access entity profile (AAEP).
The two types of VLAN-based pools are as follows:
- Dynamic pools - Managed internally by the APIC to allocate VLANs for endpoint groups (EPGs). A VMware vCenter domain can associate only to a dynamic pool. This is the pool type that is required for VMM integration.
- Static pools - The EPG has a relation to the domain, and the domain has a relation to the pool. The pool contains a range of encapsulated VLANs and VXLANs. For static EPG deployment, the user defines the interface and the encapsulation. The encapsulation must be within the range of a pool that is associated with a domain with which the EPG is associated.
An AEP provisions the VLAN pool (and associated VLANs) on the leaf. The VLANs are not actually enabled on the port. No traffic flows unless an EPG is deployed on the port. Without VLAN pool deployment using an AEP, a VLAN is not enabled on the leaf port even if an EPG is provisioned. Infrastructure VLAN is required for AVS communication to the fabric using the OpenFlex control channel.
Now that this is all clear, we can configure, for example, a Virtual Port Channel between our Leaf Switches and an external Nexus Switch. In our case, we are using the Nexus5548 (5.2). Physical Connectivity to ACI will generally be handled using the Access Policies. There is a bit non-intuitive procedure that needs to be followed here, so lets go through it together:
1.1 Create the Interface Policies you need.You only need to create the Interface Policies if you need a Policy on the Interface that is different then the Default policy. For example, the default LLDP state is ENABLE, so if you want to enable the LLDP – just use the default policy. In this case you will most probably need only the Port-Channel Policy, because the Default Port-Channel policy enables the “ON” mode (Static Port-Channel).
1.2 Create the Switch Policy.This is the step where you will have to choose the Physical Leaf Switches where you need to apply your Policy. In our case we will choose the both Leaf Switches (101 and 102). This is done under Switch Policies -> Policies -> Virtual Port Channel Default.
1.3 Create the Interface Policy Group.In this step you will need to create the Group that gathers the Interface Policies you want to use on the vPC. This means that we need to create a vPC Interface Policy Group and
1.4 Create the Interface Profile.This is the step that will let you specify on which ports the vPC will be configured. In our case we want to choose the interface e1/3 of each Leaf.
1.5 Create the Switch Profile.Switch Profile lets you choose the exact Leaf Switches you want the policy applied on, and select the previously configured Interface Profile to specify the vPC Interfaces on each of those leaf switches.
Check if everything is in order:
Nexus# show port-channel summary…3 Po3(SU) Eth LACP Eth1/17(P) Eth1/18(P)
Leaf1# show vpc extLegend: (*) - local vPC is down, forwarding via vPC peer-link
vPC domain id : 10Peer status : peer adjacency formed okvPC keep-alive status : DisabledConfiguration consistency status : successPer-vlan consistency status : successType-2 consistency status : successvPC role : primaryNumber of vPCs configured : 1Peer Gateway : DisabledDual-active excluded VLANs : -Graceful Consistency Check : EnabledAuto-recovery status : Enabled (timeout = 240 seconds)Operational Layer3 Peer : Disabled
vPC Peer-link status---------------------------------------------------------------------id Port Status Active vlans-- ---- ------ --------------------------------------------------1 up -
vPC status---------------------------------------------------------------------------------id Port Status Consistency Reason Active vlans Bndl Grp Name-- ---- ------ ----------- ------ ------------ ----------------1 Po1 up success success - vPC_101_102IMPORTANT: ID and port-channel number (Po#) are automatically created and will vary. Notice no active VLANs. They will appear once you have created and associated an AEP.
Multicast is also allowed in the ACI Fabric, the MCAST trees are built, and in the case of failure there is a FRR (Fast Re-Route). The ACI Fabric knows the MCAST tree, and drops the MCAST exactly on the ports of the leaf Switches where the MCAST frames are supposed to go. This might be a bit confusing, when you consider that ACI actually STRIPS the encapsulation to save the Bandwidth when the frame gets to the Leaf Port (this applies to all external encapsulations: dot1x, VxLAN, nvGRE…), and adds it back on when the “exit” leaf needs to forward the frame to the external network.
2. Tenant(s) and 3. VRF are the concepts that I think are clear enough even from the official Cisco documentation, so I wont go too deep into it.
4. Bridge Domains and EPGsOnce you create the Bridge Domain, you need to define the Subnets that will reside within the Bridge Domain. These Subnets are used as the Default Gateway within the ACI Fabric, and the Default Gateway of the Subnet is equivalent to the SVI on a Switch.
In our case we created a Bridge Domain called “ACI_Local_BD”, and decided to interconnect 2 Physical PCs with different subnets, and see if they can ping if we put them in the same EPG. In order to do this we created the following Subnets within the EPG:
- 172.2.1.0/24 with the GW 172.2.1.1 (configured as a Private IP on ACI Fabric, and as the Principal GW within the Bridge Domain)
- 172.2.2.0/24 with the GW 172.2.2.1 (configured as a Private IP on ACI Fabric)
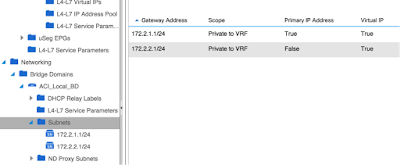
Once we have the BD and the Subnets created, we need to define the EPG(s). Since in our case we are treating the Physical Servers, we know exactly what physical port of each Leaf they are plugged to. This means that the easiest way to assign the Physical Servers to the EPG is to define the Static Bindings.
IMPORTANT: If you use the Static Bindings (Leafs), all the ports within the Leaf you configure will statically belong to the EPG.
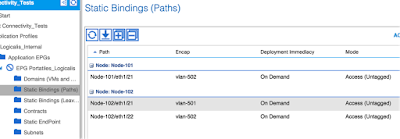
In our case we configured the ports e1/21 and e1/22 of the Leaf1, and the port e1/21 of the Leaf 1 (Node1), as shown on the screenshot below.
TIP: In one moment you will need to manually define the encapsulation of the traffic coming from this Node within the ACI Fabric. This is not the number of the Access VLAN on the Leaf port that VLAN will be locally assigned by the Leaf. This is a VLAN that needs to be from the VLAN Pool you defined for the Physical Domain.
Now comes the “cool” part (at least for the Networking guys). We will check what is happening with the VLANs on the Leaf Switches.
Leaf2# show vlan extended
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
7 infra:default active Eth1/1, Eth1/5
8 Connectivity_Tests:ACI_Local_BD active Eth1/21, Eth1/22
9 Connectivity_Tests:Logicalis_Int active Eth1/22
ernal:Portatiles_Logicalis
10 Connectivity_Tests:Logicalis_Int active Eth1/21
ernal:Portatiles_Logicalis
VLAN Type Vlan-mode Encap
---- ----- ---------- -------------------------------
7 enet CE vxlan-16777209, vlan-4093
8 enet CE vxlan-16121790
9 enet CE vlan-502
10 enet CE vlan-501
Leaf1# show vlan ext
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
7 infra:default active Eth1/1, Eth1/5
10 Connectivity_Tests:ACI_Local_BD active Eth1/21
11 Connectivity_Tests:Logicalis_Int active Eth1/21
ernal:Portatiles_Logicalis
VLAN Type Vlan-mode Encap
---- ----- ---------- -------------------------------
7 enet CE vxlan-16777209, vlan-4093
10 enet CE vxlan-16121790
11 enet CE vlan-502
First of all, have in mind that the VLANs have only the local importance on the Switch; they are NOT propagated within the ACI Fabric. Notice the following VLANs in the previous output:
- VLAN 7: The default infra VLAN. This VLAN has no importance at all. The important part of the output is the column “Encapsulation”, where the VxLAN 16777209 and VLAN 4093 (Default Infrastructure for real) appear. These 2 entities carry the traffic between Spines and the Leafs.
- VLANs 8, 9, 10 and 11 are also not important for ACI, only for the Leafs. This means that on the Leaf Ports there is a “Switchport access VLAN 8” command configured. The important parts are the VLANs 501 and 502, which carry the traffic within the ACI Fabric.
If you focus on how the local leaves VLANs are named, you will figure out the following structure: Tenant -> ANP -> EPG. This is done by the ACI, t give you a bettwe preview of what these local VLANs are for.
5. ANP and 6. Contracts will not be explained at this moment.
7. Virtual Machine Manager Integration
Virtual Machine Manager Domain or VMM Domain - Groups VM controllers with similar networking policy requirements. For example, the VM controllers can share VLAN or Virtual Extensible Local Area Network (VXLAN) space and application endpoint groups (EPGs).
The APIC communicates with the controller to publish network configurations such as port groups that are then applied to the virtual workloads.
Note: A single VMM domain can contain multiple instances of VM controllers, but they must be from the same vendor (for example, from VMware or from Microsoft).
The objective here is to create a VMM Domain. Upon creating the VMM domain, APIC will populate the datacenter object in vCenter with a virtual distributed switch (VDS). You need to create a VLAN pool to be associated with the VMM domain. Have in mind that the VLAN Pools configuration is Global to the ACI Fabric because the VLANs apply to physical Leaf Switches, and they are configured at "Fabric-Access Policies-Pools" menu.
Apart from this, you will need to actually create the VMM Domain (VM Networking Menu), and define the Hypervisor IP and credentials and associate the previously created AEP to your VMM Domain. Once you have the VMM Domain created and all the hosts in the new VDS, you need to associate your EPGs with the VMM Domain, in order to add the Endpoints from the Hypervisor to the EPG.
TIP: Don´t forget that you need to add the ESXi hosts to your newly created VDS manually, from vSphere.
8. RBAC - Works exactly the same like a RBAC (Role Based Access Policy) on any Cisco platform.
9. Layer 2 and 3 External Connectivity
L2 Bridge: Packet forwarding between EP in bridge domain “BD1” and external hosts in VLAN 500 is a L2 bridge.
IMPORTANT: We need one external EPG for each L2 external connection (VLAN).
Trunking multiple VLANs over the same link requires multiple L2 External EPGs, each in a unique BD. Contract required between L2 external EPG EPG and EPG inside ACI fabric
10. Layer 4 to Layer 7 Services/Devices [Service Function Insertion]
There are 3 major steps we need to perform in order to integrate an external L4-7 Service with ACI:
- Import the Device package to ACI.
- Create the logical devices
- Create the concrete devices
The APIC uses northbound APIs for configuring the network and services. You use these APIs to create, delete, and modify a configuration using managed objects. When a service function is inserted in the service graph between applications, traffic from these applications is classified by the APIC and identified using a tag in the overlay network. Service functions use the tag to apply policies to the traffic. For the ASA integration with the APIC, the service function forwards traffic using either routed or transparent firewall operation.



